
ChatIe的相关学习及其理解
Posted on 9 2, 2024
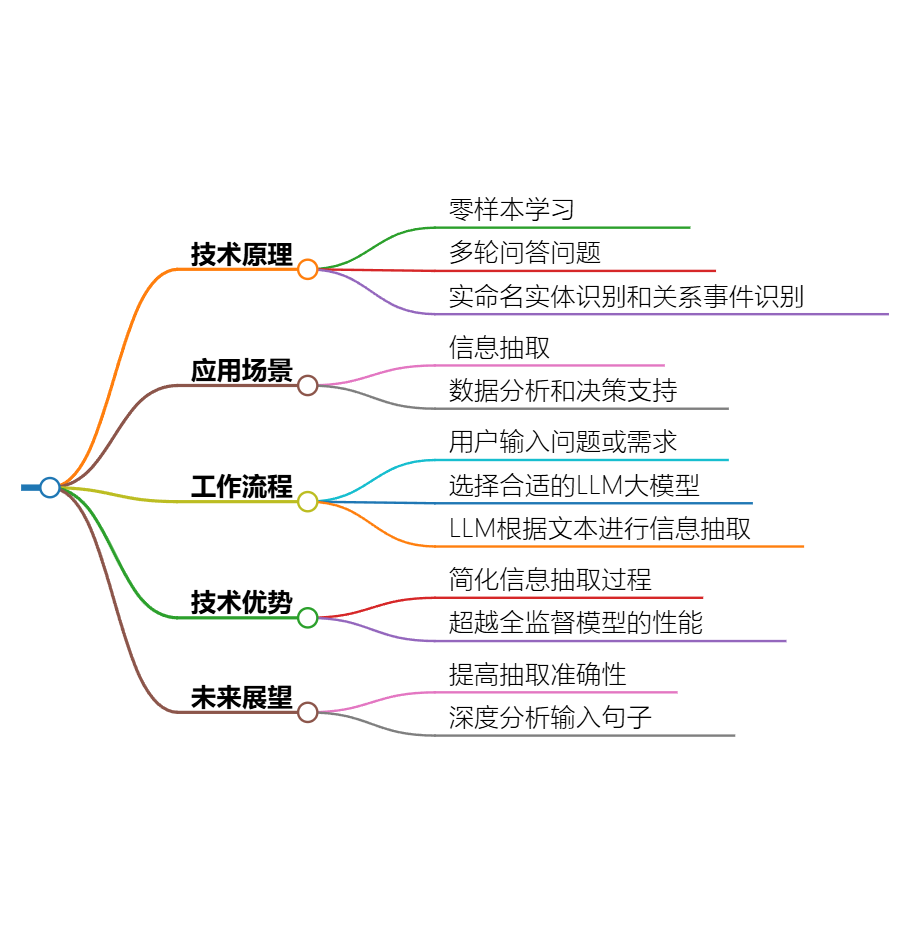
ChatIe在未来在许多方面有着更重要的功能
零样本信息抽取,这样可以节省大量的时间成本,不需要人工去标记。具体应用场景如下:
- 1. 新闻分析: 从大量新闻文章中抽取关键事件和实体关系
- 2. 学术研究: 从科研论文中抽取研究方法、结果等关键信息。
- 3. 商业智能: 从市场报告中抽取竞争对手信息、市场趋势等,医疗健康: 从病历中抽取症状、诊断、治疗等信息。
- 4. 法律文件分析: 从合同、判决书等法律文件中抽取关键条款和实体。
以下是一些实际效果图
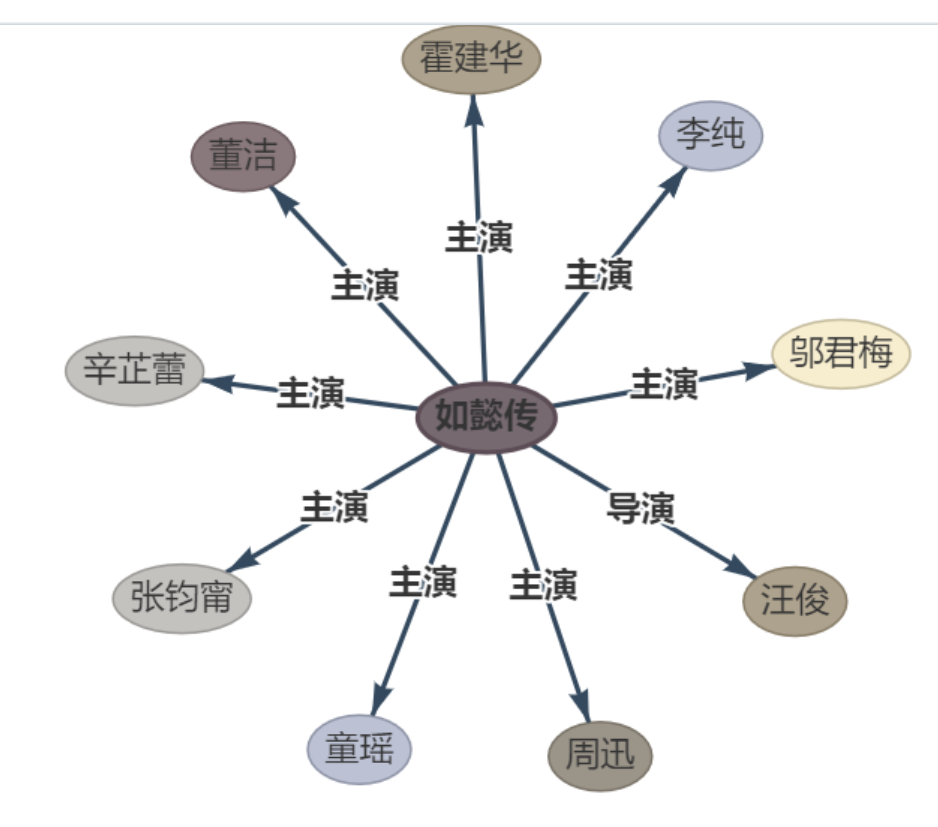
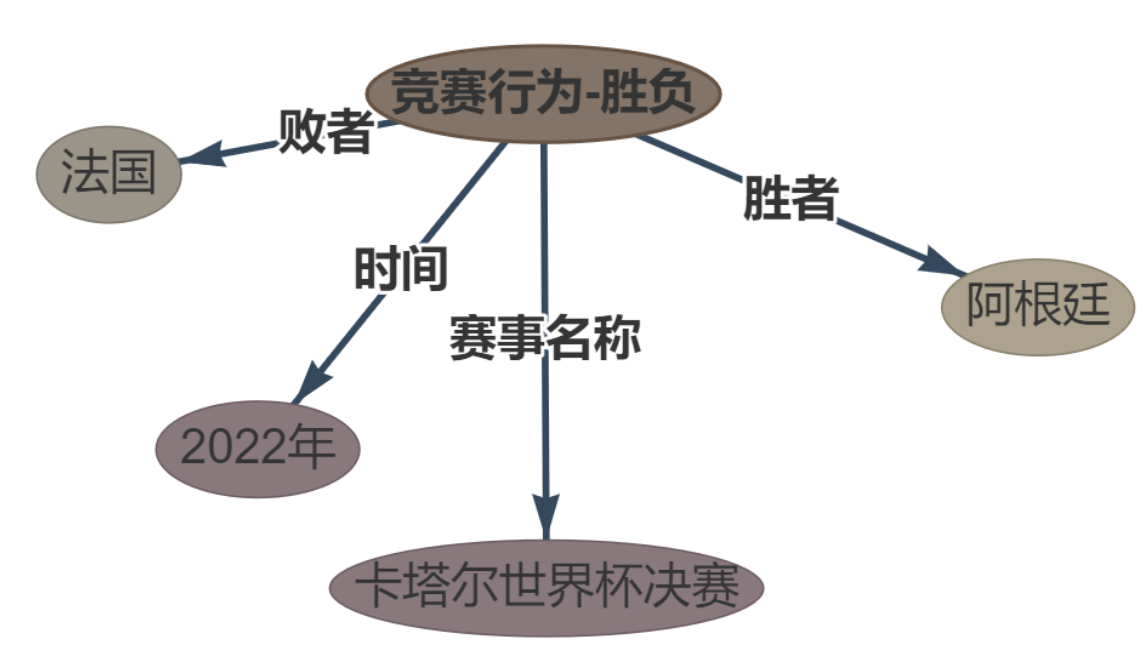
优化当中所以
以下我将详细的说明如何实现这个模型,ChatIe
插一个题外话,在今天配置过程中领悟到的一些小tips,在python的开发过程中,总是会不断的安装各种各样的库函数,如果不加镜像,下载速度又很慢,加的话每次又记不住地址,不得不又去问度娘,解决办法就是在根目录c/用户/你的用户名/,目录下创建一个pip文件夹,并且在文件夹中创建一个pip.ini,内容是[global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple,定义了一个全局的pip,这样以后在使用pip下载内容的时候,就会自动加上镜像从而节省时间
首先的在window/linux上安装node.js(这个项目需要,配置好环境变量),这里不过多赘述
然后在终端中执行npm install
- 1. cd 和 Run 下载所需的依赖项。front-endnpm install 然后在终端中执行npm install
- 2. 在该文件目录下执行npm run start
- 3. 因为此项目是前后端分离的所以再cd back-endpython run.py
- 4. 配置 Proxy 即可
在这里我卡了一下,因为我错误的认为在pycharm的终端一样可以运行,但是因为 npm 是 Node.js 的包管理工具,而不是 Python 的。Python 终端(通常是 python 或 python3 命令启动的交互式环境)只能运行 Python 代码,而不能直接运行 Node.js 或 npm 命令。
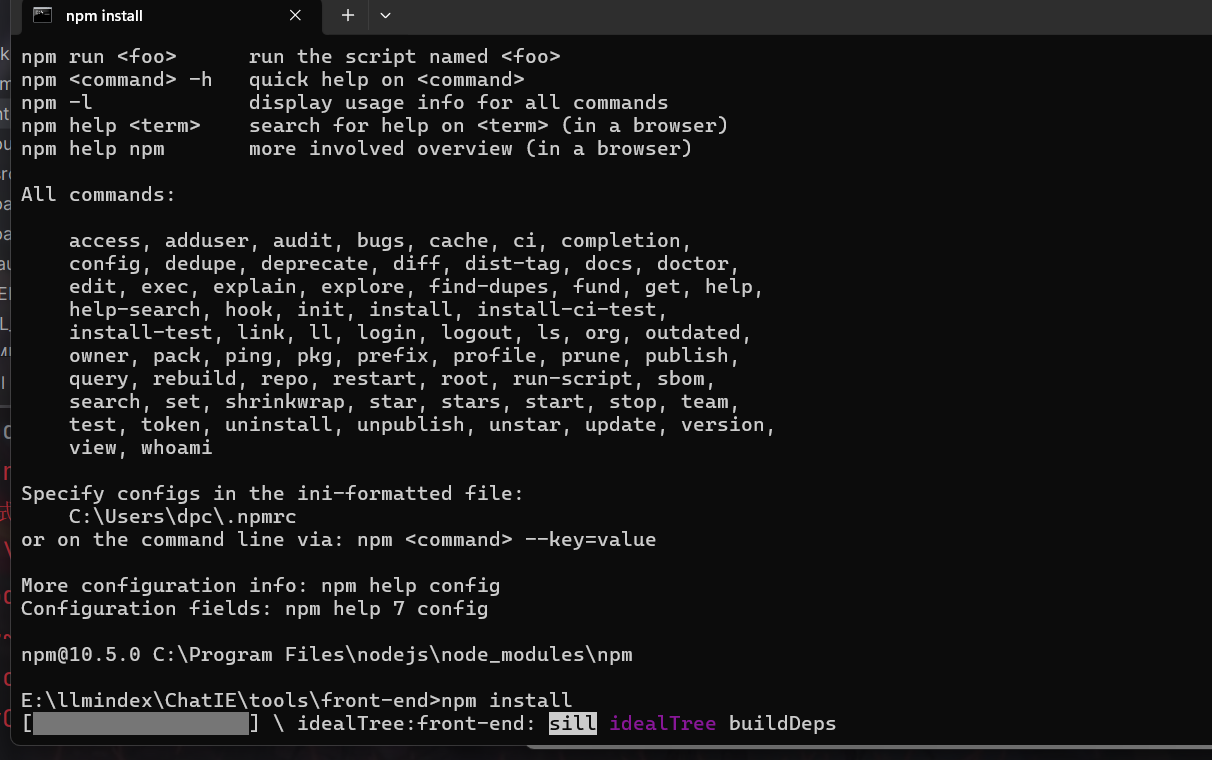
npm下载的包大部分都是从国外下载,速度很慢,将npm默认镜像改成为华为npm config set registry https://mirrors.huaweicloud.com/repository/npm/
使用这个项目需要重点下载几个包,cross-evn ,react-scripts,它可以在不同的操作系统上以相同的方式设置环境变量下载的时候需要稍微耐心一点,可能会卡着一个页面半分钟,在我操作的过程中,我就错误的以为是我的配置有问题,于是提前按ctrl c退出下载
当所有配置都完成了以后,在前端文件内再次输入 npm run start,前端页面启动成功!浏览器会自动跳转到此页面,但是现在只是空有壳子,还无法使用后端的相关内容
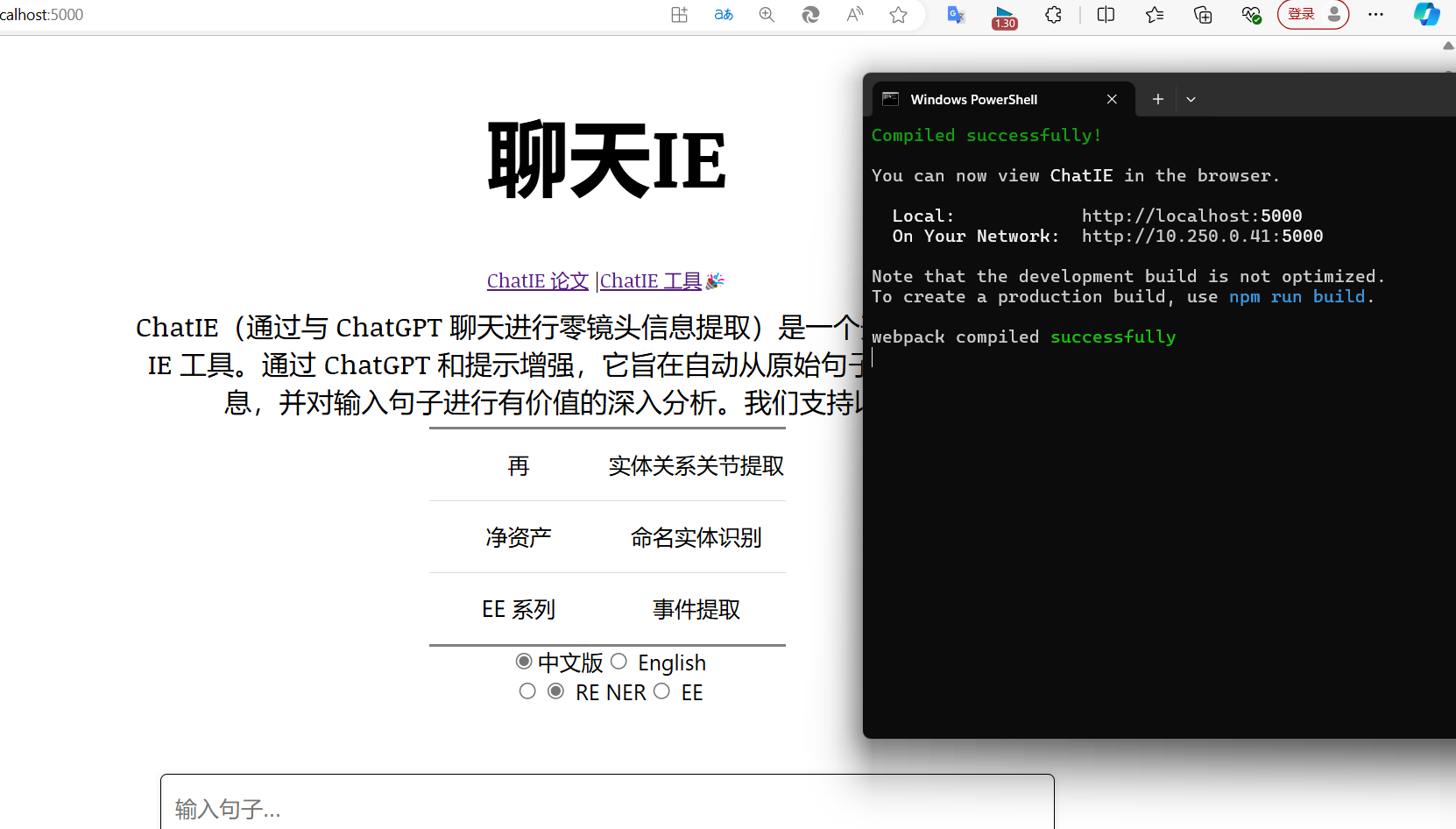
cd到后端文件夹,因为这个html使用了flask前后端 分离,所以再单独启动一下run.py文件,此时前后端就已经连接通畅了,前端输入的字符已经可以传到后端进行解析了
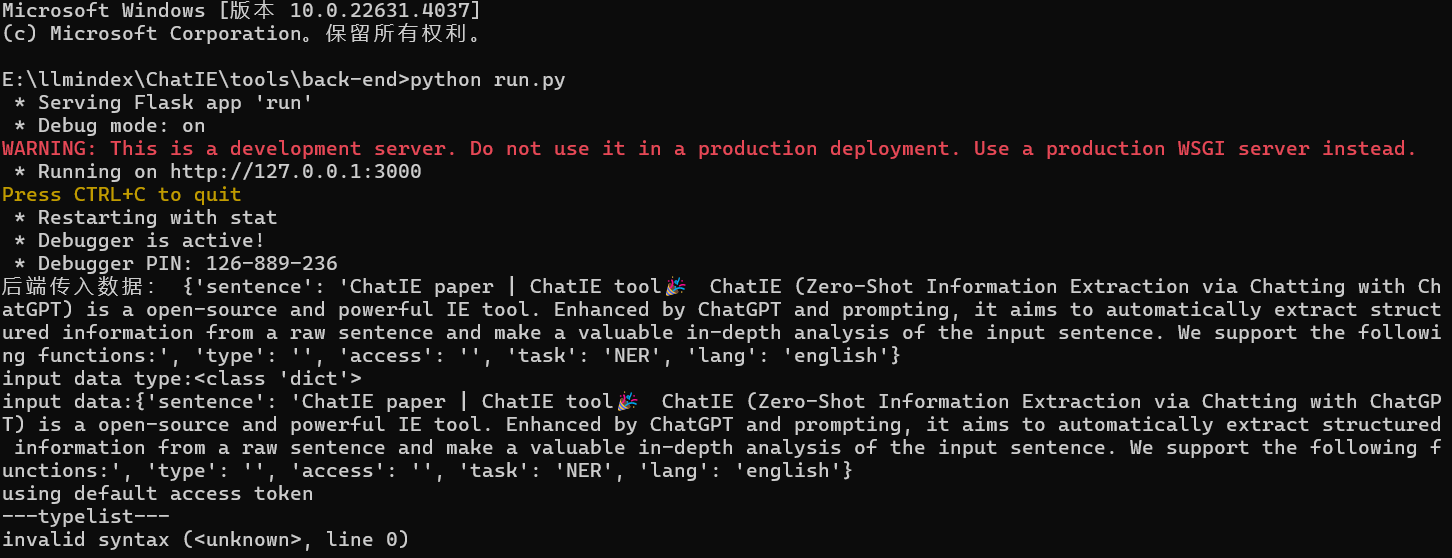
接下来说一下他的代码层面上的操作原理
首先,他将后端代码主要分为了3个文件,其中run.py和access.py两个重要的文件负责了绝大部分内容
这是run.py文件,负责接受来自前端的字符,以及其他要求(参数要求)
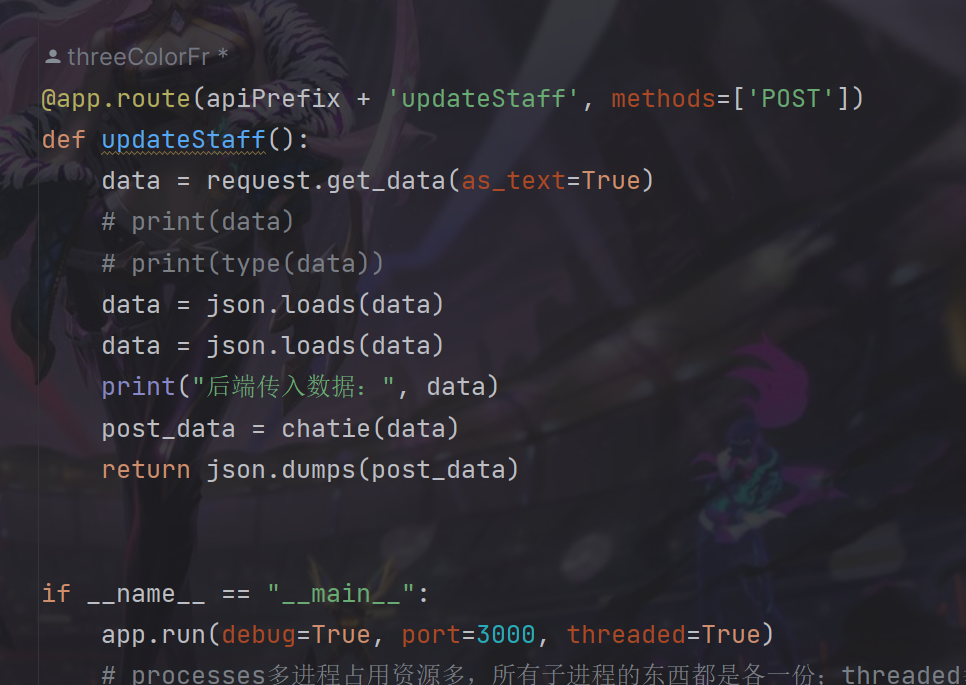
数据进来之后到access文件进行逻辑判定以及请求openai api
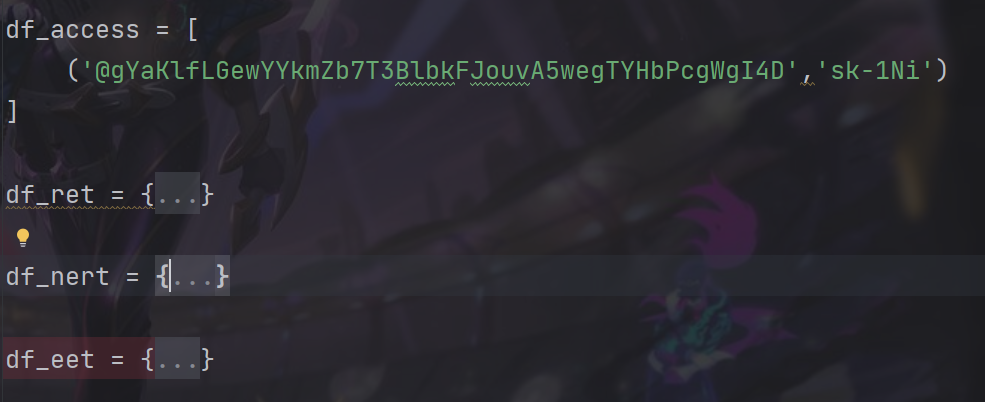
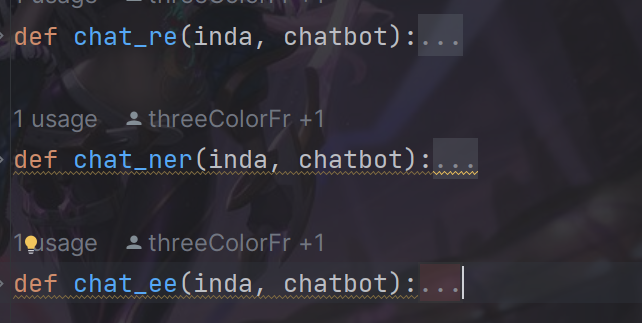
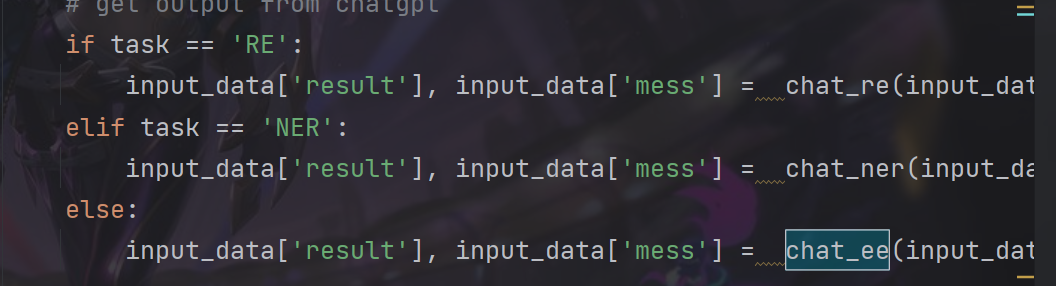
在access文件中会对要处理的字符类型框架进行判断,目前chatie中有三种框架对应三种方法,当然每个方法核心都是一样的,会有许多重复功能的函数,比如请求api,向openai输入对应的框架
总的来说
输入的数据 通常是字符串形式的文字或英文字母。首先,这些数据会经过精心设计的 Python逻辑 转换成相应的格式。随后,处理过的数据会被输入到 ChatGPT 中,并结合预设的框架,让 ChatGPT 填充内容。