
Got模型的部署及其使用
Posted on 10 8, 2024
GOT的模型介绍
GOT-OCR2.0是一款新一代的光学字符识别(OCR)技术,标志着人工智能在文本识别领域的重大进步。作为一款开源模型,GOT-OCR2.0不仅支持传统的文本和文档识别,还能够处理乐谱、图表以及复杂的数学公式,为用户提供了更加全面和高效的解决方案。
- 1. 多语言支持:GOT-OCR2.0 主要支持中文和英文字符识别,并能够通过进一步的微调扩展到更多语言。这种灵活性使其适用于国际化应用,满足不同用户的需求。
- 2. 场景文本识别:该系统能够处理自然场景中的文本识别任务,例如街道标志、广告牌上的文字等。这一功能使得 GOT-OCR2.0 在各种实际应用中表现出色。
- 3. 文档 OCR:GOT-OCR2.0 能够处理文档中完整页面的文字识别,无论是纯文本文档,还是含有表格、公式等复杂内容的文档。这一功能极大地方便了文档数字化和信息管理。
- 4. 格式化文本 OCR:该系统支持将光学文档中的文本直接转换为 Markdown、LaTeX 等格式,保持复杂文档的原始排版和格式。这使得后续编辑和排版工作更加高效。
- 5. 动态分辨率处理:GOT-OCR2.0 采用动态分辨率技术,支持对超高分辨率图像(如大幅海报、拼接 PDF 页面)进行 OCR 处理,确保在图像过大时仍能保持较高的识别准确性。
- 6. 多页 OCR:该系统能够批量处理多页文档,例如长篇 PDF 文件或包含多张图片的 OCR 任务,显著提升了处理效率。这对于需要大量文档处理的用户尤为重要。
- 7. 公式、表格与图表识别:除了基本文本识别,GOT-OCR2.0 还能够识别和处理文档中的数学公式、化学分子式、表格及图表等复杂结构,并将其转换为可编辑格式(如 LaTeX 或 Python 字典格式),满足更专业的需求。
以下是一些实际效果图


GOT模型的部署
以下我将详细的说明安装过程中常出现的问题
前置条件
首先的在window/linux上安装, 创建虚拟环境,避免环境冲突,严格要求torch,cuda版本一致,这里使用的版本是环境是 cuda11.8+torch2.0.1,python=3.10
下载库函数的过程中,库函数flash-attention会出现许多问题,这里单独说一下这个环境的安装
flash-attention的安装
常见安装如下
-

-

-

-

-

以上问题都解决以后,在下载flash之前,还需要下载ninja,这样可以加速falsh的下载速度,官方显示的正常下载时间可能要几个小时,有了ninja以后可能几分钟即可完成
-

还需要判断ninja是否生效,输入以下指令,返回结果为0,才可以快速下载
-

错误类型1
错误类型2
由于改库是从git仓库当中下载,所以下载之前需要初始话git 使用git init
如果是在linux系统下载flash attention 可能会出现终端保持一个界面长时间不动,就算有问题也不会显示,可以使用以下命令,将错误日志保存本地
GOT的模型的使用
这里着重讲一下如何的调用这个模型
- 1.首先git GOT这个项目以后cd到GOT文件夹下
- 2.去下载权重文件这里提供三个地址1. 百度云盘提取码:OCR2 2. Huggingface 3.Google Drive
- 3.下载以后需要将权重文件放在与GOT同一目录下,权重文件1.4gb左右
- 4.
- 5.然后需要cd的以下文件下再启动
- 6.

- 7.直接启动会提示找不到got
- 8.

- 6.
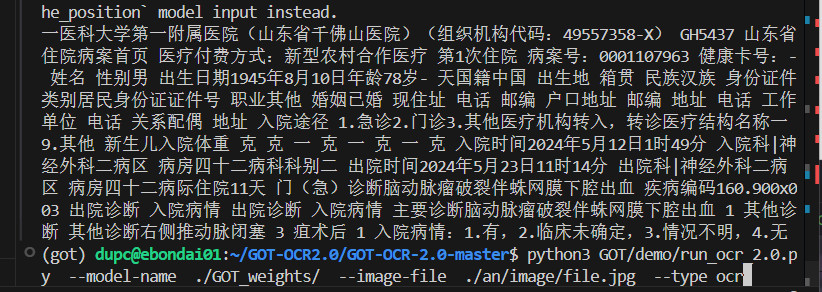
需要使用export PYTHONPATH=/home/dupc/GOT-OCR2.0/GOT-OCR-2.0-master:$PYTHONPATH,或者去.bashrc文件设置一下全局变量
这时候再启动该模型即可返回结果